
What Is an Agent Harness? Why Your LLM Needs More Than an API Call (Part 1)

Series: The Agent Harness — Part 1 of 12
Most LLM apps fail not because the model is bad. They fail because there’s nothing holding the model together.
The API call works. The prompt is well-crafted. The model returns smart answers. But the moment you add tools, multi-step tasks, user interruptions, or context that outlasts a single request — things fall apart. The agent loses track. It repeats work. It can’t recover from errors. It runs forever on a task that should have stopped three steps ago.
That gap — between “LLM API” and “production-grade autonomous agent” — is what an Agent Harness fills.
This series uses Claude Code as a detailed case study. Not because Claude Code is the only way to build agent infrastructure, but because it’s one of the most production-hardened agent harnesses publicly available, and Anthropic’s source was briefly exposed in 2026 — giving the engineering community an unusually detailed look at how a serious agent harness is actually built.
Claude Code is our case study. Your agent is the goal.
In this first post, we’ll establish the foundational question: what exactly is an Agent Harness, what does it need to provide, and how do you know when you need one?
The Problem: LLMs Are Not Agents
Here’s the counterintuitive truth about LLMs: they’re stateless. Every API call is independent. The model has no memory between calls, no ability to act on the world, no way to know what it did two minutes ago unless you explicitly tell it.
That’s fine for single-shot tasks. Ask a question, get an answer. Translate this text. Summarize this document.
But the moment your use case involves steps — read this file, understand what’s in it, decide what to change, write the change, run the tests, fix what broke — you’ve left the territory where a simple API call suffices.
You need infrastructure that provides what the model fundamentally cannot:
| What the model lacks | What the harness provides |
|---|---|
| State across calls | Session management, message history |
| Memory between sessions | Persistent memory files, project context |
| The ability to act | Tool registration and dispatch |
| Safe action execution | Permission pipeline, sandboxing |
| Recovery from errors | Retry logic, graceful degradation |
| Handling context limits | Compression, summarization |
| Real-time output | Streaming architecture |
| Extensibility | Plugin/hook systems |
None of these are model problems. They’re infrastructure problems. And solving them properly is the difference between a demo and a production system.
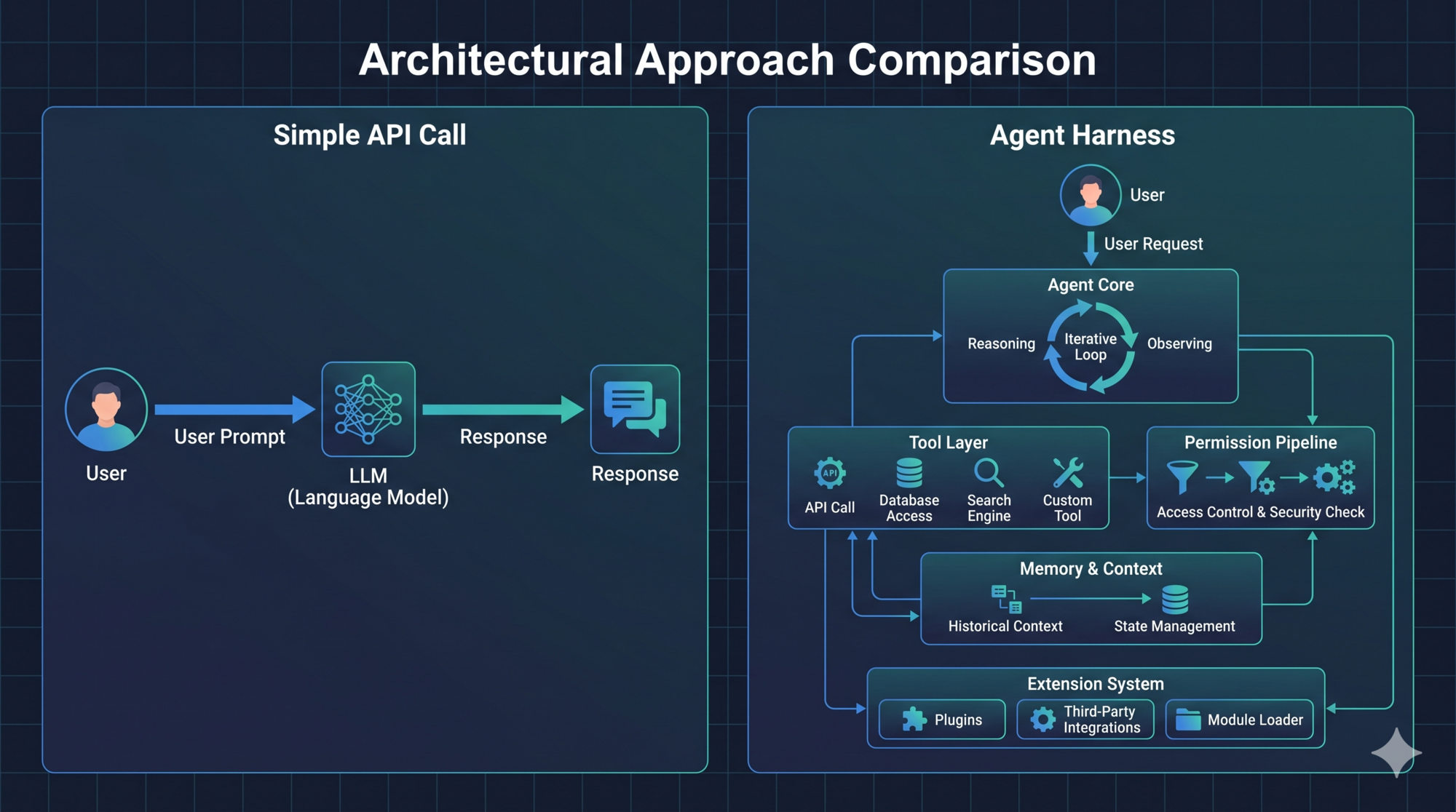
The Three-Tier Spectrum
Not every project needs a full Agent Harness. The right architecture depends on what your task actually requires. There’s a spectrum with three clear points:
Tier 1: Simple API Call
When to use it: Single-turn tasks with no side effects. Translation. Classification. Summarization. Answering a specific question.
A simple API call is prompt → response. No tools, no loop, no state. The model does one thing and returns.
Most LLM tutorials live here. Most production LLM apps start here and stay here longer than they should.
Tier 2: Function Calling
When to use it: Single-turn tasks that need to interact with external data. Querying a database. Looking up an API. Fetching a document and reasoning about it.
Function calling (also called tool use) lets the model call a predefined function and reason about its output — still within a single request-response pair, or a small, bounded number of calls.
Tier 3: Full Agent Harness
When to use it: Multi-turn autonomous loops with side effects, where the number of steps cannot be predetermined.
If your task requires:
- The agent to decide its next action based on intermediate results (not a fixed pipeline)
- Side effects — writing files, running commands, modifying external systems
- Cost control and safety — you need to be able to stop, audit, and limit what the agent does
- Recovery — the agent needs to handle partial failures and keep going
- Sessions that span multiple interactions
…then you need a harness.
| Dimension | Simple API | Function Calling | Agent Harness |
|---|---|---|---|
| Interaction turns | One | Small, bounded | Many, unbounded |
| Tool requirements | None | One or few | Many, complex |
| Context management | None | Manual | Automatic compression |
| Error recovery | Retry | Retry | Multi-layer (fallback, circuit breaker) |
| Cost control | Low (single call) | Low | High — it accumulates |
| Safety requirements | Low (no side effects) | Medium | High (file ops, commands) |
The transition from Tier 2 to Tier 3 is not a gradual slide — it’s a conceptual jump. Once you have an autonomous loop with side effects, you’ve entered harness territory whether you realize it or not.
What Happened When Developers Skipped the Harness
Here’s a common failure pattern. A developer builds a “coding agent” using a simple loop:
while True:
response = call_llm(messages)
if response.has_tool_call:
result = execute_tool(response.tool_call)
messages.append(result)
else:
return response.text
This works in demos. Then in production:
- The LLM passes malformed parameters — the loop crashes
- The tool takes 30 seconds — no streaming, the user sees a frozen screen
- The context fills up after 10 iterations — the loop fails without explanation
- The LLM calls
rm -rfon a path the user didn’t intend to delete - Two tool calls run concurrently and corrupt a shared file
- The user presses Ctrl+C halfway through — the agent leaves things in a broken state
Each of these is not a model problem. They’re infrastructure problems. And they’re exactly what an Agent Harness exists to solve.
Design lesson: A
while Trueloop with an API call inside is the beginning of an agent, not a finished one. The harness is everything around the loop that makes it safe, recoverable, observable, and usable.
Case Study: Claude Code’s Agent Harness
Claude Code is a useful reference not because it’s the only way to build a harness, but because it’s built for one of the hardest agent tasks — autonomous software development — and it’s been running in production long enough to have worked through the edge cases.
The scale is significant: 1,884 TypeScript files, 512,664 lines of code. For context, VS Code’s core codebase is a similar size. This is not bloat — it’s a reflection of genuine engineering complexity.
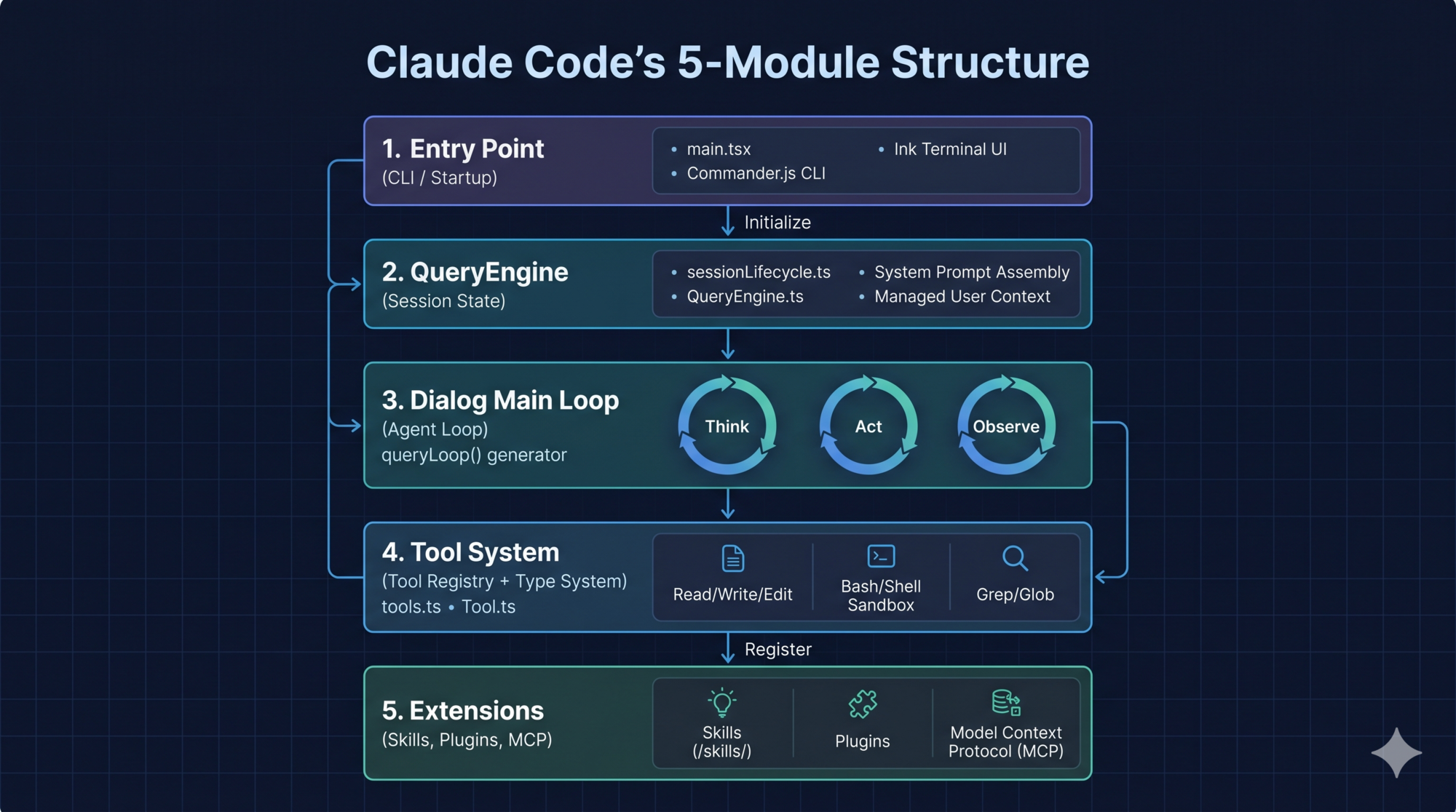
The Five Core Modules
Claude Code’s architecture can be understood through five modules with clear separation of concerns:
1. Entry Point — Startup optimization, CLI parsing, React/Ink initialization. Notably: side-effect imports are ordered so performance probes run first, then parallelized I/O prefetching, then module loading. Startup time is treated as a first-class concern.
2. QueryEngine — The session state owner. One instance per session, persisting message history, file cache, usage statistics, and permission denial records across turns. Encapsulates state so it has a single owner.
3. Dialog Main Loop — The async generator that implements the ReAct cycle: construct API request → call LLM → parse tool calls → validate permissions → execute tools → inject results → decide whether to continue. We’ll go deep on this in Part 2.
4. Tool Type System — The interface contract every tool must implement. Defines: execution logic, input schema, permission model, UI rendering, concurrency safety, interrupt behavior, and destructiveness flags. The compiler enforces this contract.
5. Tool Registry — The single source of truth for all available tools. Handles conditional registration (feature flags), lazy loading (avoid circular deps, reduce startup), and tool filtering (visibility rules before sending to the LLM).
Technology Stack
| Component | Choice | Why |
|---|---|---|
| Runtime | Bun | Native TypeScript, faster startup, native fetch |
| Terminal UI | React + Ink | Declarative rendering in terminal using React component model |
| CLI | Commander.js | Mature, well-tested command parsing |
| Schema validation | Zod v4 | Runtime type safety + JSON Schema generation from one definition |
| LLM SDK | @anthropic-ai/sdk | Streaming support, type safety, retry logic |
The Zod choice is particularly instructive: it serves as the single source of truth for tool input definitions. The same Zod schema validates runtime parameters, generates JSON Schema for the API, and produces TypeScript types for the compiler. Three concerns, one definition.
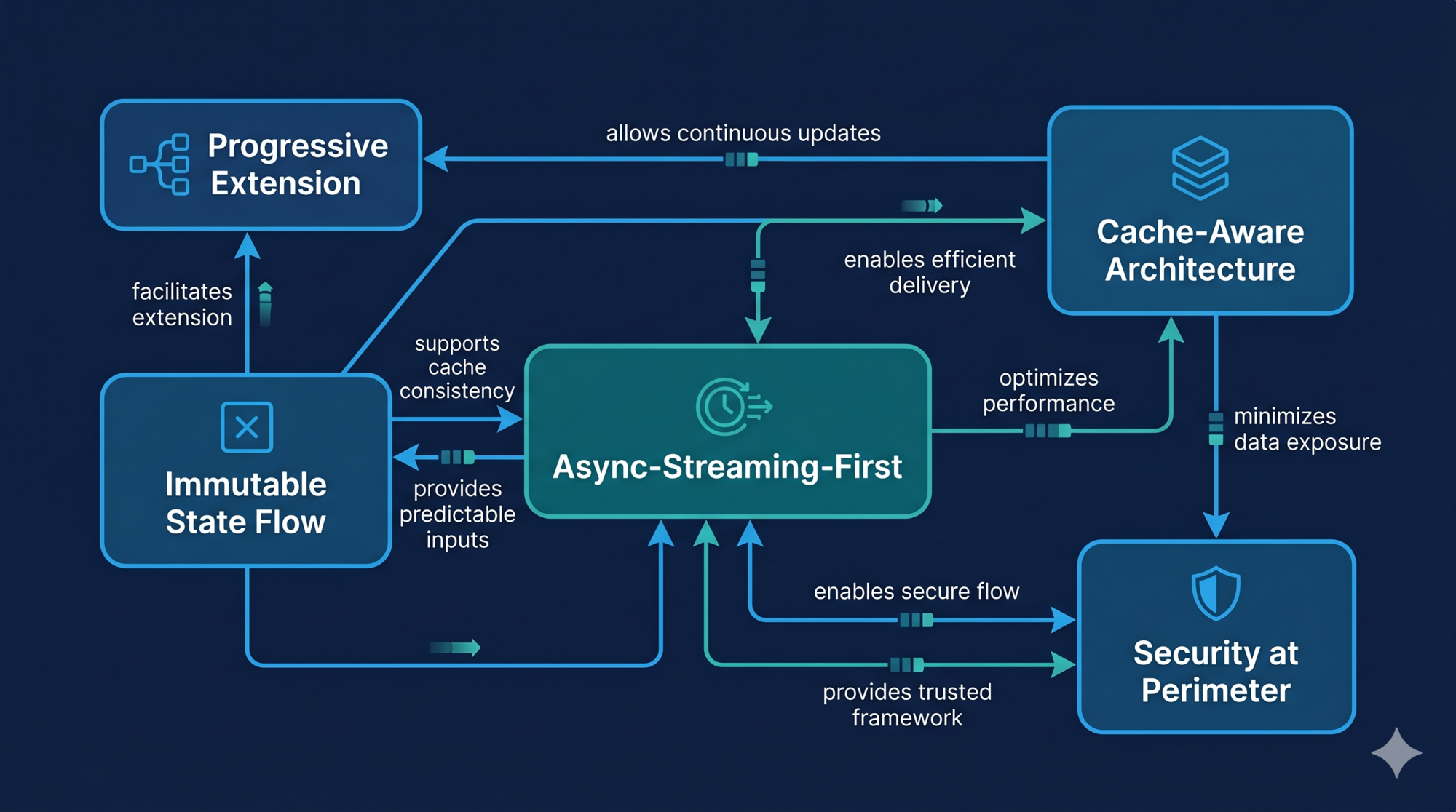
The Five Design Principles
Looking at Claude Code’s architecture, five principles emerge that run through every design decision. These aren’t Claude-specific — they’re transferable to any Agent Harness. Understanding why each principle exists matters more than the principle itself.
Principle 1: Async-Streaming-First
The entire dialog loop is built on AsyncGenerator. This isn’t a preference — it’s the only pattern that simultaneously satisfies three requirements:
- Streaming output — yield intermediate states in real time as they happen
- Cancellability — the caller can terminate the generator at any time
- Backpressure control — if the consumer falls behind, the generator automatically pauses
A callback-based approach gives you streaming but loses cancellation. Promises give you cancellation but lose streaming. EventEmitter introduces memory leak risks and loses type safety. AsyncGenerator is the unique intersection.
The practical implication: every layer of the system — tool execution, context compression, model responses — flows through the same yield-based pipeline. The UI layer consumes it with a for await...of loop and renders incrementally.
Principle 2: Security at the Perimeter
The permission system isn’t bolted on after the fact — it’s embedded in the core pipeline. Every tool call must pass through four independent checkpoints before execution:
- Tool visibility filtering — forbidden tools are filtered out before the LLM even sees them
- Input validation — parameters are validated against the Zod schema
- Permission decision — evaluated against permission mode, tool danger level, user history
- Runtime protection — sandbox restrictions, timeout controls, output size limits
This is Defense in Depth. Each checkpoint can independently block an operation. No single layer is a “silver bullet.”
The key insight: security that’s context-aware requires multiple layers. rm -rf node_modules is safe in a dev environment. rm -rf /etc is catastrophic. The same tool, the same command pattern — completely different risk levels depending on context. A flat allowlist can’t handle this. A pipeline can.
Principle 3: Cache-Aware Architecture
LLM API costs accumulate fast in agent scenarios (many API calls per session). Claude Code’s architecture is designed to maximize prompt cache hits:
- System prompts are constructed to be byte-stable when tool lists don’t change
- Sub-agents inherit the parent’s rendered system prompt (no regeneration)
- Message history is append-only — existing messages are never modified, preserving cache keys
This isn’t a performance optimization added later. It’s a constraint that shaped the immutable state design.
Principle 4: Progressive Capability Extension
Four levels of extension, each serving a different contributor:
| Level | Mechanism | Who uses it |
|---|---|---|
| Tool | Implement the Tool interface | Core developers |
| Skill | Markdown + scripts | Advanced users |
| Plugin | Lifecycle-equipped toolkits | Ecosystem developers |
| MCP Server | Standard external protocol | Third-party developers |
Each level builds on the previous. Simple needs don’t require building an MCP server. Complex third-party integrations don’t require forking the core.
Principle 5: Immutable State Flow
State is updated through wholesale replacement, not field-by-field mutation. Each iteration of the dialog loop destructures the previous state, processes it, and produces a new state object.
Benefits that matter in agent contexts: state changes are traceable and debuggable; sub-agents can safely receive state snapshots without accidentally modifying shared state; rollback becomes simple.
Design lesson: These five principles don’t operate independently. Cache-Aware architecture is only possible because of Immutable State. Security at the Perimeter works because of Async-Streaming (tools pass through the permission pipeline before yielding results). Design principles in good systems form a mutually reinforcing network, not a checklist.
The Six Engineering Challenges You’ll Face
Whether you’re building with Claude Code as inspiration or from scratch, you’ll encounter the same six infrastructure problems:
1. Tool Registration and Discovery — Who manages the registry? How does the model know which tools exist? How do you add tools dynamically without restarting?
2. Parameter Validation — The model will pass malformed parameters. Who validates them? At which layer? If you validate inside each tool, you duplicate logic. If you validate uniformly outside, you miss tool-specific rules.
3. Permission Control — Some operations are safe in some contexts, dangerous in others. A flat allowlist can’t handle this. You need a pipeline that evaluates context.
4. Error Recovery — Tool calls fail. APIs time out. LLM output doesn’t match expected format. Without a unified error recovery framework, every failure requires individual handling and the code bloats.
5. State Consistency — Multiple tool calls operate on shared resources. How do you prevent “reading stale data”? How do you maintain consistency across a multi-turn session?
6. Concurrency and Scheduling — Some tool calls can parallelize (read multiple files). Others must serialize (create a directory before writing to it). Intelligent scheduling is the difference between a fast agent and a slow one.
These six challenges are what Claude Code’s 512,664 lines of code are solving. They’re what you’ll be solving too, whether you realize it or not.
What This Series Covers
This is a 12-part series. Each post takes one major component of an Agent Harness, explains the generic engineering problem it solves, then shows how Claude Code’s implementation addresses it, and closes with patterns you can apply to your own agent.
Here’s the roadmap:
| Post | Topic | Core problem |
|---|---|---|
| 1 (this post) | What Is an Agent Harness? | When do you need one? |
| 2 | The Dialog Loop | How does the core loop work? |
| 3 | The Tool System | How do agents act safely? |
| 4 | The Permission Pipeline | How do you enforce safety without blocking everything? |
| 5 | Configuration as Architecture | How do you manage settings across users, projects, environments? |
| 6 | The Memory System | How do agents remember across sessions? |
| 7 | Context Management | What do you do when the context window fills up? |
| 8 | The Hook System | How do operators customize behavior without forking? |
| 9 | Multi-Agent Orchestration | When do you use sub-agents vs. coordinators? |
| 10 | Streaming Architecture | How do you make agents feel fast? |
| 11 | Plan Mode | How do you keep agents from acting before they understand? |
| 12 | Build Your Own | The practical blueprint |
You don’t need to read them in order, but the concepts build on each other. If you’re starting from scratch, start from the top.
Key Takeaways
- An Agent Harness is not a wrapper around the LLM API. It’s the runtime infrastructure that makes autonomous, multi-step, tool-using agents safe, recoverable, and production-ready.
- The transition from Tier 2 (function calling) to Tier 3 (full harness) is triggered by any combination of: unbounded loop, side effects, safety requirements, and cross-session memory.
- The six engineering challenges — registration, validation, permissions, error recovery, state consistency, concurrency — are infrastructure problems, not model problems.
- Claude Code’s five design principles (Async-Streaming-First, Security at the Perimeter, Cache-Aware, Progressive Extension, Immutable State) form a mutually reinforcing system, not a checklist.
- The right harness for your project is the minimal one that solves the challenges you actually have — not the most feature-complete one you can imagine.
What’s Next
In Part 2: The Dialog Loop — The Heartbeat of Every Autonomous Agent, we go inside the core loop:
- Why loops beat recursion for agent state management — and the three concrete reasons
- The five-phase turn lifecycle every loop must implement
- Why ten termination conditions matter more than the happy path
- How immutable state through a loop enables the kind of cancellation and debugging you need in production
- Claude Code’s AsyncGenerator implementation and what you can take from it
The loop is where the theory becomes engineering.
References
The Agent Harness concept
- Harness Design for Long-Running Application Development — Anthropic Engineering
- What Is an Agent Harness? The Infrastructure That Makes AI Agents Actually Work — Firecrawl
- Agentic Harness Engineering: LLMs as the New OS — Decoding AI
- The Anatomy of an Agent Harness — Daily Dose of Data Science
When to build agents
- Building Effective Agents — Anthropic Research
- LLM Powered Autonomous Agents — Lilian Weng
Claude Code architecture
- Claude Code Overview — Official docs
- Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems — arxiv
- 12 Agentic Harness Patterns from Claude Code — Generative Programmer


Comments